
How do you train a Minecraft bot to get from point A to B? By falling into lava repeatedly and hopefully having infinite respawns.
I came across Microsoft’s Project Malmo a few weeks ago, and I’ve been itching to play with it. Project Malmo is a mod/interface built on Minecraft for AI experimentation. It took some time to iron out a few bugs I had during the install, but it was worth it I think.
The GitHub page for Malmo provides some guidance and some challenges to solve. Here’s an interesting one for beginners like myself:
Solving a discrete maze
tutorial_6.py in the provided examples generates a simple maze of lava blocks and well, non-lava blocks. The goal is for the player to navigate himself to the lapis block (nice looking shiny blue block for the benefit of those who don’t Minecraft) without, of course, falling into the lava. Here’s a GIF of an unsuccessful attempt:
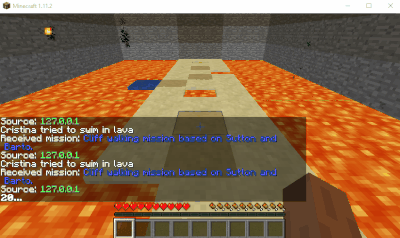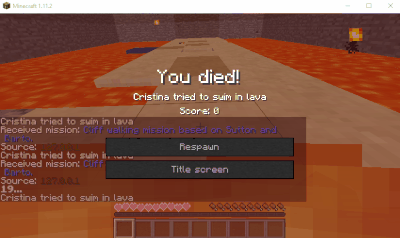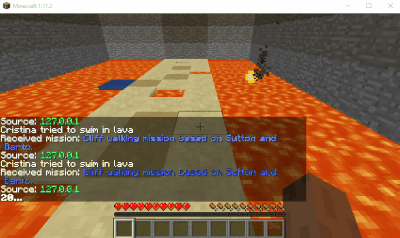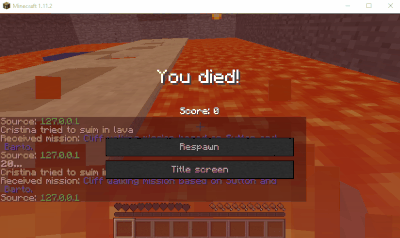
Bot repeatedly falling into the lava.
The template code already does almost all the work. The only modification that is required to make a working maze solver is to change the ‘reward’ at each state of the game/maze (i.e. after each move) so we can progressively get a better mapping of the maze and determine which moves lead to ‘better’ outcomes than others.
Default rewards
The default rewards for the mission have already been set in tutorial_6.xml, under <RewardForTouchingBlockType>. By default the reward for falling into lava is -100 and the reward for getting to the lapis block is 100. These should form the lower and upper bound of the rewards that are being returned by our algorithm (this is important later, but philosphically, surely in the context of this tiny simulation nothing can be worse than death and nothing can be better than getting to the lapis block).
Bot behaviour
Since this is a discrete 2D maze, at each game tick the bot has four possible moves to make: north, south, east or west. Specifically, it can move in the y or x axis with a value of +1 or -1. For each square on the maze (i.e. each game state), there is an associated reward value for each of the four possible moves, which defaults to 0. To move the bot, the algorithm takes the moves with the maximum associated reward value, and picks a random one. Since at the start of the game most internal moves have a value of 0 attached to them by default, the bot appears to move rather randomly (because it actually is). Each move also adds -1 to the current reward state, as a form of penalty for taking longer than necessary paths to the goal.
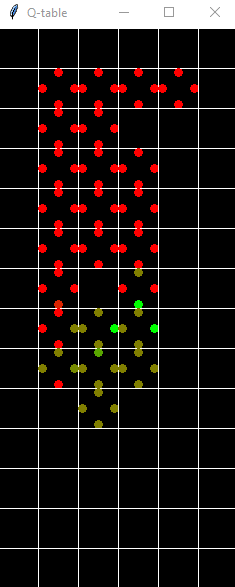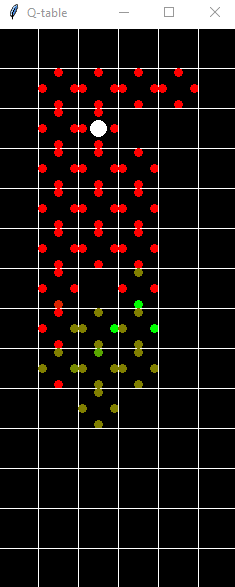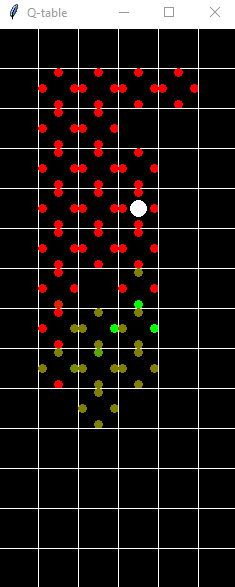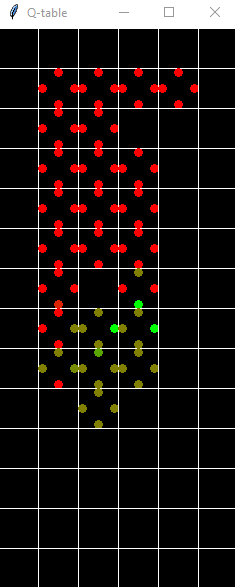
As the bot moves, the provided QTable is updated with reward of making a particular action given a game state (tile you are currently on). Here’s an example:

Q table of the transition probabilities.
As a side note, the bot makes a random move 1% (the epsilon value) of the time, because why not?
Naive solution
First, we need to update updateQTableFromTerminatingState(). This update function is called to update the reward tables when a move results in the game terminating (i.e. the player falls into a pit of lava or gets to the lapis block). We can simply update the reward value for the associated move to ‘reward’, which is either -100 or 100 depending on the cause of termination, plus some arbitrary number of -1s depending on how many moves your bot made to get here.
Then, we need to update updateQTable(). This update function is called to update the reward tables for every other move. We can simply set the new value to the old value (i.e. not changing it), since supposedly we don’t have any new information to make a better choice other than the fact the player didn’t die.
We can test this simple algorithm by running it. Turns out, this algorithm does only three things:
- Don’t walk into the lava
- If the lapis block is next to you, move there
- Move randomly otherwise
This clearly doesn’t work very well most of the time since the success of the algorithm depends on you having the great fortune to randomly stumble upon the block next to the lapis, which diminishes with increased maze size.
We clearly need a better solution that is able to progressively generate a probabilistic path towards the goal block.
Intuition
After watching many runs of the naive maze solver, it occurred to me that the main problem was that the bot cannot differentiate between which non-terminating blocks were ‘better’. There must be some way to update the reward table such that, with each success, the reward value for the blocks leading to the successful block increases recursively.
One way is to update updateQTable() after each move to some factor of the sum of all the possible moves from the current game state. For example, if my current square has a move that allows me to gain a higher reward (terminating or not), I should update the previous move to reflect that this move is a better move compared to the other possible moves in the previous game state.
Some Math
We have to determine a good ratio to factor the sum of the current square. This is important (as mentioned earlier) because we do not want our reward table values to grow to ridiculous values without bound. Since we have a pre-defined ‘max’ and ‘min reward values of 100 and -100, we can just use that as the theoretical bound.
For each square, there are four possible moves. That means the sum for each square is bounded between -400 and 400 (though in practice that is a gross overestimate, since it would reflect impossible game states, but it’s probably easier to work with this number). Suppose we average the four moves, that gives us a nice bound of -100 to 100, which fits with our max and min. The maximum is achieved when all four moves have a score of 100 i.e. all four moves lead to an immediate win (does not occur since there is only one winning tile), and the minimum is achieved when all four moves have a score of -100 i.e. all four moves lead to lava (impossible to win).
Actually writing code
We only need to modify two functions in tutorial_6.py. First, for updateQTableFromTerminatingState():
def updateQTableFromTerminatingState(self, reward):
new_q = reward
self.q_table[self.prev_s][self.prev_a]
For updateQTable():
def updateQTable(self, reward, current_state):
old_q = self.q_table[self.prev_s][self.prev_a]
sum = 0
for x in range(0, len(self.actions)):
sum += self.q_table[current_state][x]
new_q = sum / 4
self.q_table[self.prev_s][self.prev_a]
Results
Here’s some GIFs of the run after dying approximately 50 times.
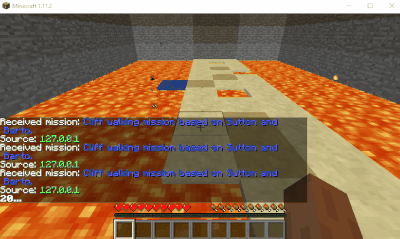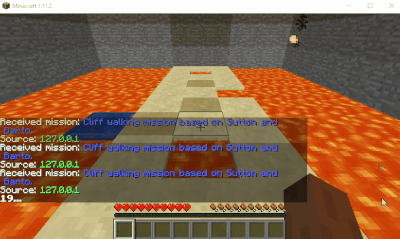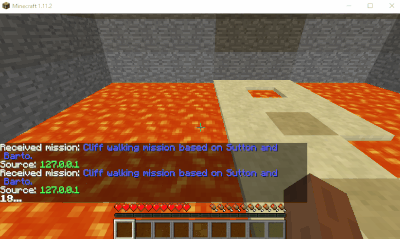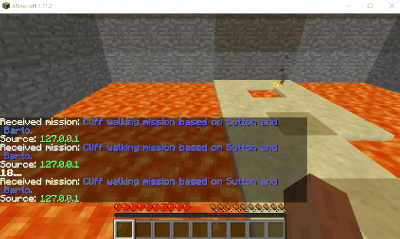
A successful bot run.
Here is a corresponding successful run displayed on the QTable.
A much better Q table of the transition probabilities.
Future Improvements
- This simple calculation of QTable probabilities is heavily weighted towards the goal tile. It is difficult for the positive value generated by the goal tile to be propagated back to the origin tile (the value gets diluted with consecutive averages)
This can be resolved by increasing the value of the positive weight of the goal tile. For example, we can implement this in updateQTableFromTerminatingState() as such:
def updateQTableFromTerminatingState(self, reward):
old_q = self.q_table
new_q = reward
self.q_table[self.prev_s][self.prev_a]
My gripe with this is that it doesn’t actually propagate that far (reward increases by a percentage less than or equal to 100% but dilution factor from averaging is constant). Furthermore, you now have reward values that grow arbitrarily large/small without bound (apparently it is fine in Python but still).
- I think a better solution can be made out of increasing the weight of the successful action and then normalizing all actions per game state such that the sum stays in the [-400,400] range. This should not be that hard (I think!).
Notes
- This solution does not necessarily find the shortest/most optimal path. It finds one that works, and generally sticks to that. You could increase the randomness factor alpha to increase the probability of making short-term non-optimal decisions that may provide a better path.