
Previously we described setting up a VM running Apache Airflow to collect credit card data in a Postgres database. The data’s not very useful sitting in a database only, so we’d have to take it out and put it somewhere. I have most of my budget and ‘money things’ worked out on a Google Spreadsheet (or GSheet), and what I’d like to do is to pipe this transaction data into the sheet to add another perspective to my accounting. The budget reflects what we’d like to have occur in reality. The transactions, well, they reflect what happened when great deals for hard disk drives pop up on Black Friday.
New Task: Exporting to GSheets
I’ve updated the repo with a new task that exports the data from Postgres to GSheets.
To actually perform the export of data to Gsheets, we use the gspread package. I highly recommend it, it is simple and straightforward. The strange thing about trying to use Google’s API is that the documentation is everywhere but where I need it. The OAuth flow works, but it grants me only access to the API, and not my sheet (which for obvious reasons we don’t make public). The gspread method is much easier:
- Create a Service Account on the developer console, and download the credentials (keys) as a JSON file.
- Share the private GSheet with the email address indicated on the Service Account, enabling read write access.
- Put the
credentials.jsonfile in the appropriate location and linkgspreadto it when initializing, and done!
Accessing the sheet and making edits is really simple with this package:
import gspread
# Get access to worksheet
gc = gspread.service_account(filename=CREDENTIALS_FILE)
spreadsheet = gc.open("My Spreadsheet Name")
worksheet = spreadsheet.worksheet("My Worksheet Name")
# Append data
my_data = ["something"]
worksheet.append_row(my_data)
I’m quite happy with this package. My minor unimportant complaint is that without looking under the hood it’s not immediately obvious how many API calls are made to Google’s server for each function call. This has led to me exhausting the API rate limit when running backfill tasks too fast, but that’s probably on me.
Backfilling With New Tasks
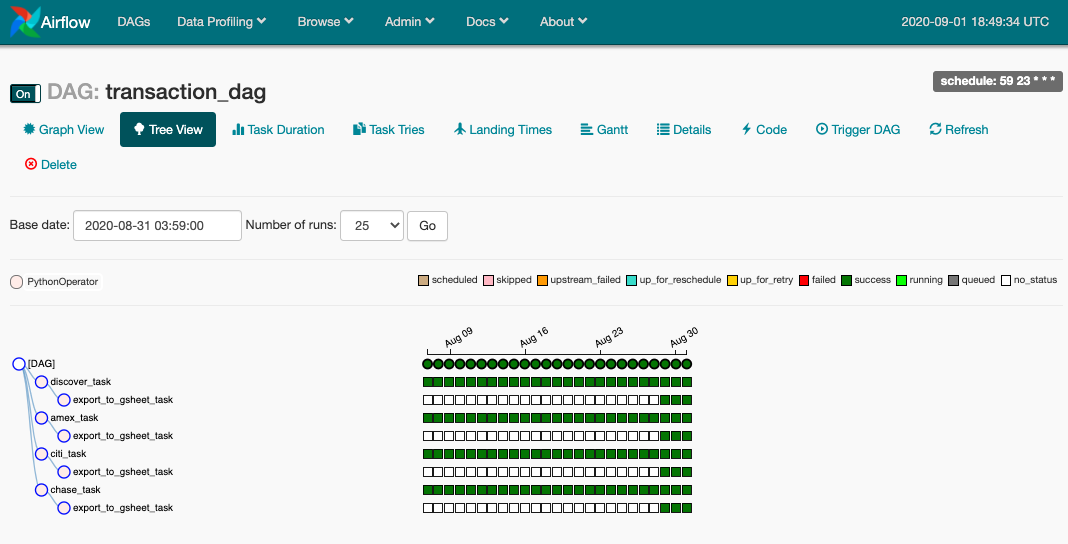
Previously we had 4 single independent tasks, so there was nothing DAG-gy about it. Now we finally add a dependency - we export our data from the database to GSheets once we finished collecting and transforming the data from all sources.
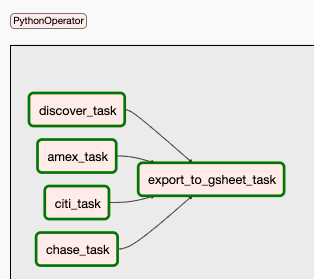
Our now very complex DAG.
This transition from 4 tasks to 5 tasks is handled fine by Airflow. If we now go back and look at old DAG runs, we’ll notice that there is now a new downstream dependent task just as in the image, but because it was a past DAG run, that task was never run. If we wish to we can run a backfill specifically on this task. One minor downside is that I had assumed that because I was appending only to my spreadsheet, the data on the spreadsheet will be sorted by date naturally. With backfills running multiple task instances in parallel however, the finish times are non-deterministic, so the output is appended with imperfect sorting. This is a small problem that can be fixed by sorting the sheet, since this is a one-time problem.
After performing our backfill to the start of the year, we can have a look at the worksheet in the GSheet we’ve been exporting to.
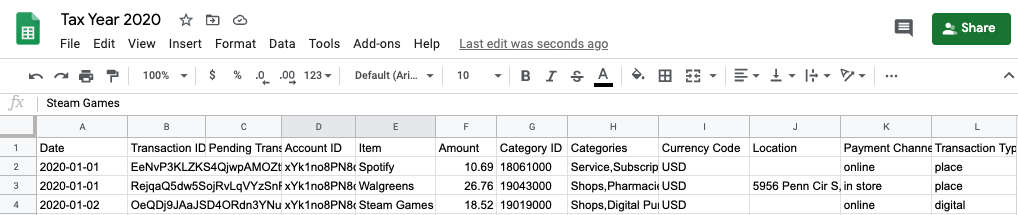
The GSheet now chock full of data.
Slapping Slack on it
This is probably a good point in time to add some monitoring to the Unraid server we’ve been running this thing on. We’re running a number of containers and VMs, some of which do things on a regular basis, so it’d be good to know if they succeeded or failed without having to login and check. Slack is probably the best option, so we setup a Slack workspace for our server, added an Airflow bot user, and passed the webhook URL to a Airflow Connection named SLACK_CONN_ID.
I borrowed this nice pair of slack operators - there’s one for success and one for failure. To integrate this into our DAG, we invoke the on_success_callback and on_failure_callback option for the Operators. Specifically, at the very last task, we add the two respective calls into the keyword arguments as follows:
# Task: Export data to GSheets
export_gsheet_task = PythonOperator(task_id="export_to_gsheet_task",
python_callable=export_to_gsheet,
provide_context=True,
on_success_callback=task_success_slack_alert,
on_failure_callback=task_fail_slack_alert)
Then, when we do a test run of the DAG, we get some results.
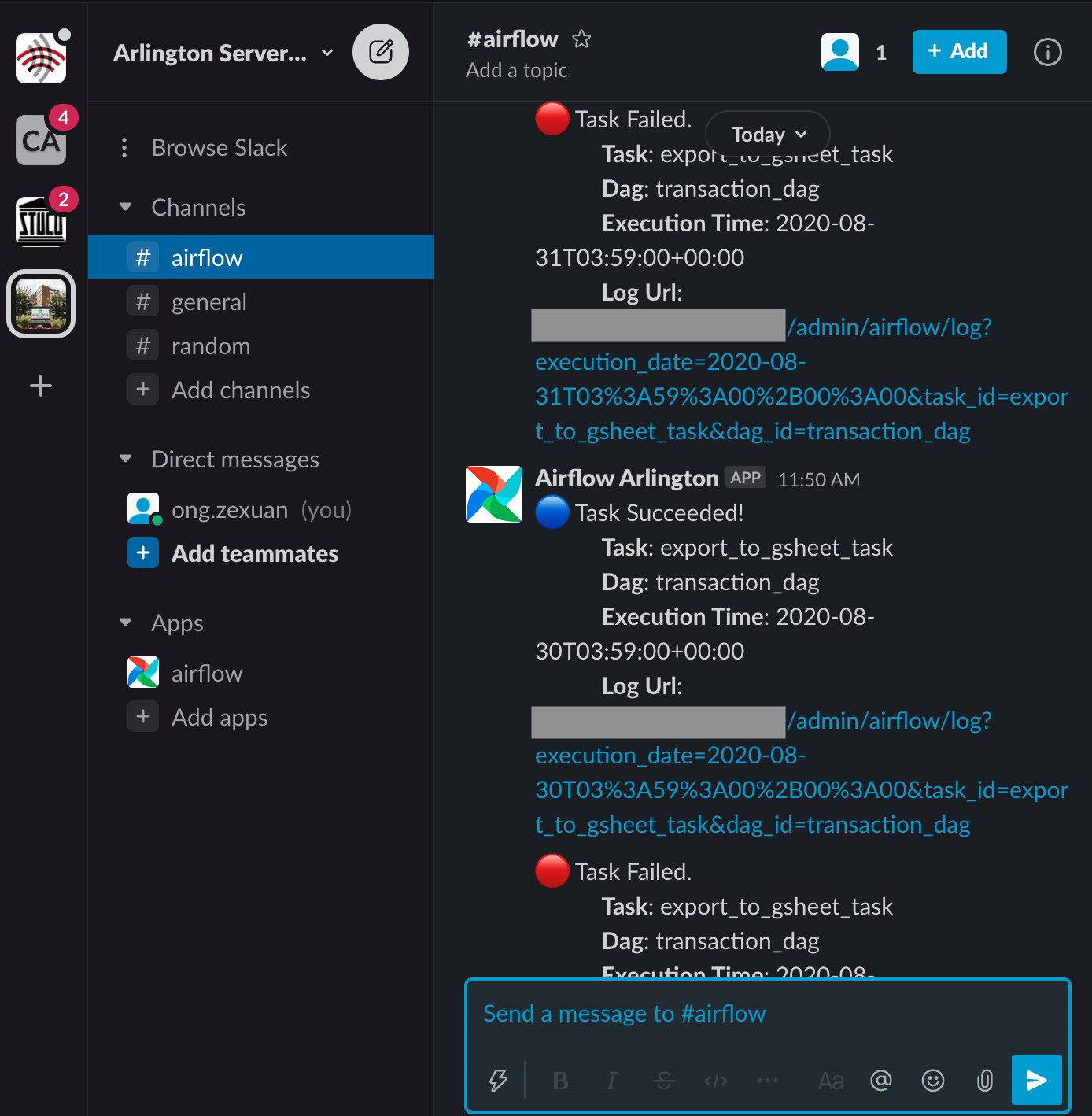
Slack notifications for the local Airflow instance. More notifications coming soon!